Model Overview
Turftopic contains implementations of a number of contemporary topic models. Some of these models might be similar to each other in a lot of aspects, but they might be different in others. It is quite important that you choose the right topic model for your use case.
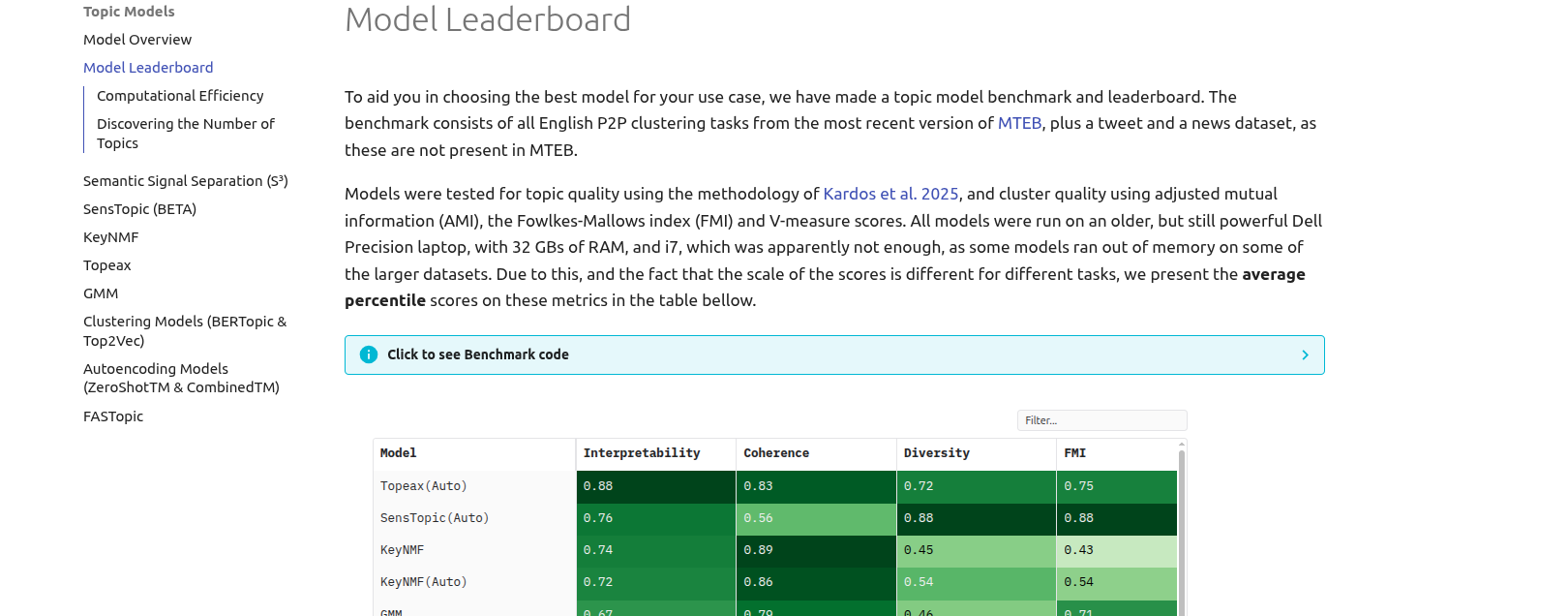
Looking for Model Performance?
If you are interested in seeing how these models perform on a bunch of datasets, and would like to base your model choice on evaluations, make sure to check out the Model Leaderboard tab:
| Model | Summary | Strengths | Weaknesses |
|---|---|---|---|
| Topeax | Density peak detection + Gaussian mixture approximation | Cluster quality, Topic quality, Stability, Automatic n-topics | Underestimates N topics, Slower, No inference for new documents |
| KeyNMF | Keyword importance estimation + matrix factorization | Reliability, Topic quality, Scalability to large corpora and long documents | Automatic topic number detection, Multilingual performance, Sometimes includes stop words |
| SensTopic(BETA) | Regularized Semi-nonnegative matrix factorization in embedding space | Very fast, High quality topics and clusters, Can assign multiple soft clusters to documents, GPU support | Automatic n-topics is not too good |
| GMM | Soft clustering with Gaussian Mixtures and soft-cTF-IDF | Reliability, Speed, Cluster quality | Manual n-topics, Lower quality keywords, Curse of dimensionality |
| FASTopic | Neural topic modelling with Dual Semantic-relation Reconstruction | High quality topics and clusters, GPU support | Very slow, Memory hungry, Manual n-topics |
| \(S^3\) | Semantic axis discovery in embedding space | Fastest, Human-readable topics | Axes can be very unintuitive, Manual n-topics |
| BERTopic and Top2Vec | Embed -> Reduce -> Cluster | Flexible, Feature rich | Slow, Unreliable and unstable, Wildly overestimates number of clusters, Low topic and cluster quality |
| AutoEncodingTopicModel | Discover topics by generating BoW with a variational autoencoder | GPU-support | Slow, Sometimes low quality topics |
Different models will naturally be good at different things, because they conceptualize topics differently for instance:
BERTopic,Top2Vec,GMMandTopeaxfind clusters of documents and treats those as topicsKeyNMF,SensTopic,FASTopicandAutoEncodingTopicModelconceptualize topics as latent nonnegative factors that generate the documents.SemanticSignalSeparation(\(S^3\)) conceptualizes topics as semantic axes, along which topics are distributed.
You can find a detailed overview of how each of these models work in their respective tabs.
Model Features
Some models are also capable of being used in a dynamic context, some can be fitted online, some can detect the number of topics for you and some can detect topic hierarchies. You can find an overview of these features in the table below.
| Model |  Multiple Topics per Document Multiple Topics per Document |
 Detecting Number of Topics Detecting Number of Topics |
 Dynamic Modeling Dynamic Modeling |
 Hierarchical Modeling Hierarchical Modeling |
 Inference over New Documents Inference over New Documents |
 Cross-Lingual Cross-Lingual |
 Online Fitting Online Fitting |
|---|---|---|---|---|---|---|---|
| KeyNMF |  |
|
|
|
|
|
|
| SensTopic | |
|
|
 |
|
|
|
| Topeax | |
|
|
|
|
|
|
| SemanticSignalSeparation | |
|
|
|
|
|
|
| ClusteringTopicModel | |
|
|
|
|
|
|
| GMM | |
|
|
|
|
|
|
| AutoEncodingTopicModel | |
|
|
|
|
|
|
| FASTopic | |
|
|
|
|
|
|
Model API Reference
turftopic.base.ContextualModel
Bases: BaseEstimator, TransformerMixin, TopicContainer
Base class for contextual topic models in Turftopic.
Source code in turftopic/base.py
22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 | |
encode_documents(raw_documents)
Encodes documents with the sentence encoder of the topic model.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
raw_documents |
Iterable[str]
|
Textual documents to encode. |
required |
Return
ndarray of shape (n_documents, n_dimensions) Matrix of document embeddings.
Source code in turftopic/base.py
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | |
fit(raw_documents, y=None, embeddings=None)
Fits model on the given corpus.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
raw_documents |
Documents to fit the model on. |
required | |
y |
Ignored, exists for sklearn compatibility. |
None
|
|
embeddings |
Optional[ndarray]
|
Precomputed document encodings. |
None
|
Source code in turftopic/base.py
84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | |
fit_transform(raw_documents, y=None, embeddings=None)
abstractmethod
Fits model and infers topic importances for each document.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
raw_documents |
Documents to fit the model on. |
required | |
y |
Ignored, exists for sklearn compatibility. |
None
|
|
embeddings |
Optional[ndarray]
|
Precomputed document encodings. |
None
|
Returns:
| Type | Description |
|---|---|
ndarray of shape (n_documents, n_topics)
|
Document-topic matrix. |
Source code in turftopic/base.py
62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | |
get_feature_names_out()
Get topic ids.
Returns:
| Type | Description |
|---|---|
ndarray of shape (n_topics)
|
IDs for each output feature of the model. This is useful, since some models have outlier detection, and this gets -1 as ID, instead of its index. |
Source code in turftopic/base.py
111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 | |
get_vocab()
Get vocabulary of the model.
Returns:
| Type | Description |
|---|---|
ndarray of shape (n_vocab)
|
All terms in the vocabulary. |
Source code in turftopic/base.py
101 102 103 104 105 106 107 108 109 | |
prepare_topic_data(corpus, embeddings=None)
Produces topic inference data for a given corpus, that can be then used and reused. Exists to allow visualizations out of the box with topicwizard.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
corpus |
List[str]
|
Documents to infer topical content for. |
required |
embeddings |
Optional[ndarray]
|
Embeddings of documents. |
None
|
Returns:
| Type | Description |
|---|---|
TopicData
|
Information about topical inference in a dictionary. |
Source code in turftopic/base.py
129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 | |
push_to_hub(repo_id)
Uploads model to HuggingFace Hub
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
repo_id |
str
|
Repository to upload the model to. |
required |
Source code in turftopic/base.py
200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 | |
to_disk(out_dir)
Persists model to directory on your machine.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
out_dir |
Union[Path, str]
|
Directory to save the model to. |
required |
Source code in turftopic/base.py
179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 | |