Using Turftopic
To get started using Turftopic you will need to load and fit a topic model. This page provides more in-depth information on how to do these.
from turftopic import KeyNMF
model = KeyNMF(20).fit(corpus)
Important Attributes
In Turftopic all models have a vectorizer and an encoder component, which you can specify when initializing a model.
- The vectorizer is used to turn documents into Bag-of-Words representations and learning the vocabulary. The default used in the package is sklearn's
CountVectorizer. - The encoder is used to encode documents, and optionally the vocabulary into contextual representations. This will most frequently be a Sentence Transformer. The default in Turftopic is
all-MiniLM-L6-v2, a very lightweight English model.
You can use any of the built-in encoders in Turftopic to encode your documents, or any sentence transformer from the HuggingFace Hub. This allows you to use embeddings of different quality and computational efficiency for different purposes.
Here's a model that uses E5 large as the embedding model, and only learns words that occur in at least 20 documents.
from turftopic import SemanticSignalSeparation
from sklearn.feature_extraction.text import CountVectorizer
model = SemanticSignalSeparation(10, encoder="all-MiniLM-L6-v2", vectorizer=CountVectorizer(min_df=20))
You can also use external models for encoding, here's an example with OpenAI's embedding models:
from turftopic import GMM
from turftopic.encoders import OpenAIEmbeddings
model = GMM(10, encoder=OpenAIEmbeddings("text-embedding-3-large"))
If you intend to, you can also use n-grams as features instead of words:
from turftopic import GMM
from sklearn.feature_extraction.text import CountVectorizer
model = GMM(10, vectorizer=CountVectorizer(ngram_range=(2,4)))
Fitting Models
All models in Turftopic have a fit() method, that takes a textual corpus in the form of an iterable of strings.
Beware that the iterable has to be reusable, as models have to do multiple passes over the corpus.
corpus: list[str] = ["this is a a document", "this is yet another document", ...]
model.fit(corpus)
Prompting Embedding Models
Some embedding models can be used together with prompting, or encode queries and passages differently. This can significantly influence performance, especially in the case of models that are based on retrieval (KeyNMF) or clustering (ClusteringTopicModel). Microsoft's E5 models are, for instance all prompted by default, and it would be detrimental to performance not to do so yourself.
In these cases, you're better off NOT passing a string to Turftopic models, but explicitly loading the model using sentence-transformers.
Here's an example for clustering models:
from turftopic import ClusteringTopicModel
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer(
"intfloat/multilingual-e5-large-instruct",
prompts={
"query": "Instruct: Cluster documents according to the topic they are about. Query: "
"passage": "Passage: "
},
# Make sure to set default prompt to query!
default_prompt_name="query",
)
model = ClusteringTopicModel(encoder=encoder)
You can also use instruct models for keyword retrieval with KeyNMF. In this case, documents will serve as the queries and words as the passages:
from turftopic import KeyNMF
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer(
"intfloat/multilingual-e5-large-instruct",
prompts={
"query": "Instruct: Retrieve relevant keywords from the given document. Query: "
"passage": "Passage: "
},
# Make sure to set default prompt to query!
default_prompt_name="query",
)
model = KeyNMF(10, encoder=encoder)
When using KeyNMF with E5, make sure to specify the prompts even if you're not using instruct models:
encoder = SentenceTransformer(
"intfloat/e5-large-v2",
prompts={
"query": "query: "
"passage": "passage: "
},
# Make sure to set default prompt to query!
default_prompt_name="query",
)
model = KeyNMF(10, encoder=encoder)
Setting the default prompt to query is especially important, when you are precomputing embeddings, as query should always be your default prompt to embed documents with.
Precomputing Embeddings
In order to cut down on costs/computational load when fitting multiple models in a row, you might want to encode the documents before fitting a model. Encoding the corpus is the heaviest part of the process and you can spare yourself a lot of time by only doing it once.
Some models have to encode the vocabulary as well, this cannot be done before inference, as the models learn the vocabulary itself from the corpus.
The fit() method of all models takes and embeddings argument, that allows you to pass a precooked embedding matrix along to fitting.
One thing to watch out for is that you have to pass the embedding model along to the model that was used for encoding the corpus.
This is again, to ensure that the vocabulary gets encoded with the same embedding model as the documents.
Here's a snippet of correct usage:
import numpy as np
from sentence_transformers import SentenceTransformer
from turftopic import GMM, ClusteringTopicModel
encoder = SentenceTransformer("intfloat/e5-large-v2", prompts={"query": "query: ", "passage": "passage: "}, default_prompt_name="query")
corpus: list[str] = ["this is a a document", "this is yet another document", ...]
embeddings = np.asarray(encoder.encode(corpus))
gmm = GMM(10, encoder=encoder).fit(corpus, embeddings=embeddings)
clustering = ClusteringTopicModel(encoder=encoder).fit(corpus, embeddings=embeddings)
Inference
In order to get the importance of each topic for the documents in the corpus, you might want to use fit_transform() instead of fit()
document_topic_matrix = model.fit_transform(corpus)
This will give you a matrix, where every row is a document and every column represents the importance of a given topic.
You can infer topical content for new documents with a fitted model using the transform() method (beware that this only works with inductive methods):
document_topic_matrix = model.transform(new_documents, embeddings=None)
Note that using
fit()andtransform()in succession is not the same as usingfit_transform()and the later should be preferred under all circumstances. For one, not all models have atransform()method, butfit_transform()is also way more efficient, as documents don't have to be encoded twice. Some models have additional optimizations going on when usingfit_transform(), and thefit()method typically usesfit_transform()in the background.
Interpreting Models
Turftopic comes with a number of pretty printing utilities for interpreting the models.
To see the highest the most important words for each topic, use the print_topics() method.
model.print_topics()
| Topic ID | Top 10 Words |
|---|---|
| 0 | armenians, armenian, armenia, turks, turkish, genocide, azerbaijan, soviet, turkey, azerbaijani |
| 1 | sale, price, shipping, offer, sell, prices, interested, 00, games, selling |
| 2 | christians, christian, bible, christianity, church, god, scripture, faith, jesus, sin |
| 3 | encryption, chip, clipper, nsa, security, secure, privacy, encrypted, crypto, cryptography |
| .... |
# Print highest ranking documents for topic 0
model.print_representative_documents(0, corpus, document_topic_matrix)
| Document | Score |
|---|---|
| Poor 'Poly'. I see you're preparing the groundwork for yet another retreat from your... | 0.40 |
| Then you must be living in an alternate universe. Where were they? An Appeal to Mankind During the... | 0.40 |
| It is 'Serdar', 'kocaoglan'. Just love it. Well, it could be your head wasn't screwed on just right... | 0.39 |
model.print_topic_distribution(
"I think guns should definitely banned from all public institutions, such as schools."
)
| Topic name | Score |
|---|---|
| 7_gun_guns_firearms_weapons | 0.05 |
| 17_mail_address_email_send | 0.00 |
| 3_encryption_chip_clipper_nsa | 0.00 |
| 19_baseball_pitching_pitcher_hitter | 0.00 |
| 11_graphics_software_program_3d | 0.00 |
If you want to share these results, you can also export all tables, by using the export_<something> method instead of print_<something>.
csv_table: str = model.export_topic_distribution("something something", format="csv")
latex_table: str = model.export_topics(format="latex")
md_table: str = model.export_representative_documents(0, corpus, document_topic_matrix, format="markdown")
Manual topic naming
You can manually name topics in Turftopic models after having interpreted them. If you find a more fitting name for a topic, feel free to rename it in your model.
from turftopic import SemanticSignalSeparation
model = SemanticSignalSeparation(10).fit(corpus)
model.rename_topics({0: "New name for topic 0", 5: "New name for topic 5"})
Automated topic naming
You can also use large language models, or other NLP techniques to assign human-readable names to topics. Here is an example of using ChatGPT to generate topic names from the highest ranking keywords.
Read more about namer models here.
from turftopic import KeyNMF
from turftopic.namers import OpenAITopicNamer
namer = OpenAITopicNamer("gpt-4o-mini")
model.rename_topics(namer)
model.print_topics()
| Topic ID | Topic Name | Highest Ranking |
|---|---|---|
| 0 | Operating Systems and Software | windows, dos, os, ms, microsoft, unix, nt, memory, program, apps |
| 1 | Atheism and Belief Systems | atheism, atheist, atheists, belief, religion, religious, theists, beliefs, believe, faith |
| 2 | Computer Architecture and Performance | motherboard, ram, memory, cpu, bios, isa, speed, 486, bus, performance |
| 3 | Storage Technologies | disk, drive, scsi, drives, disks, floppy, ide, dos, controller, boot |
| 4 | Moral Philosophy and Ethics | morality, moral, objective, immoral, morals, subjective, morally, society, animals, species |
| 5 | Christian Faith and Beliefs | christian, bible, christians, god, christianity, religion, jesus, faith, religious, biblical |
| 6 | Serial Modem Connectivity | modem, port, serial, modems, ports, uart, pc, connect, fax, 9600 |
| 7 | Graphics Card Drivers | card, drivers, monitor, vga, driver, cards, ati, graphics, diamond, monitors |
| 8 | Windows File Management | file, files, ftp, bmp, windows, program, directory, bitmap, win3, zip |
| 9 | Printer Font Management | printer, print, fonts, printing, font, printers, hp, driver, deskjet, prints |
Visualization
Turftopic does not come with built-in visualization utilities, topicwizard, a package for interactive topic model interpretation is fully compatible with Turftopic models.
pip install topic-wizard
By far the easiest way to visualize your models for interpretation is to launch the topicwizard web app.
import topicwizard
topicwizard.visualize(model=model, corpus=corpus)
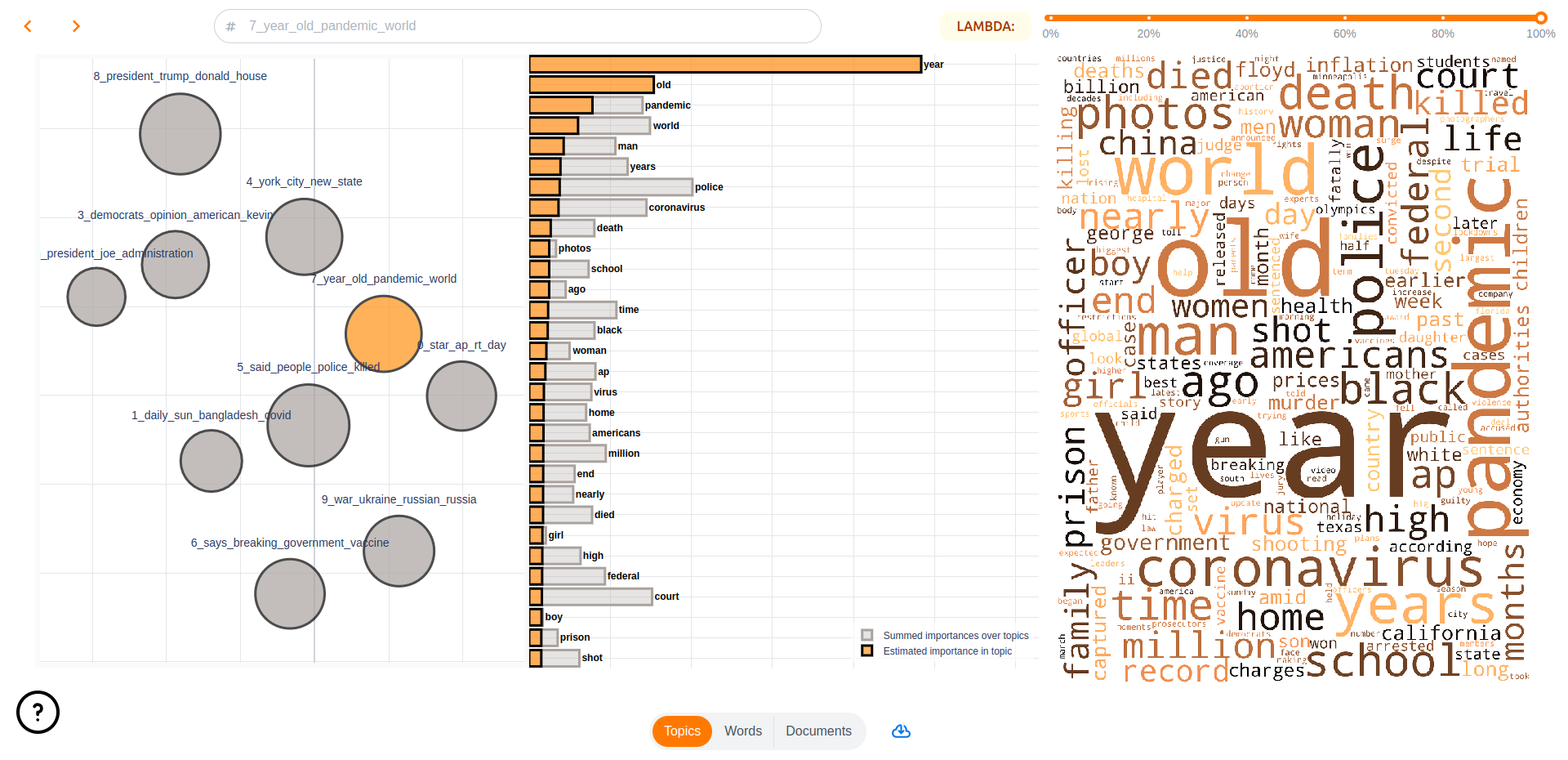
You can also produce individual interactive figures using the Figures API in topicwizard.